Conclusion
Solution oveview
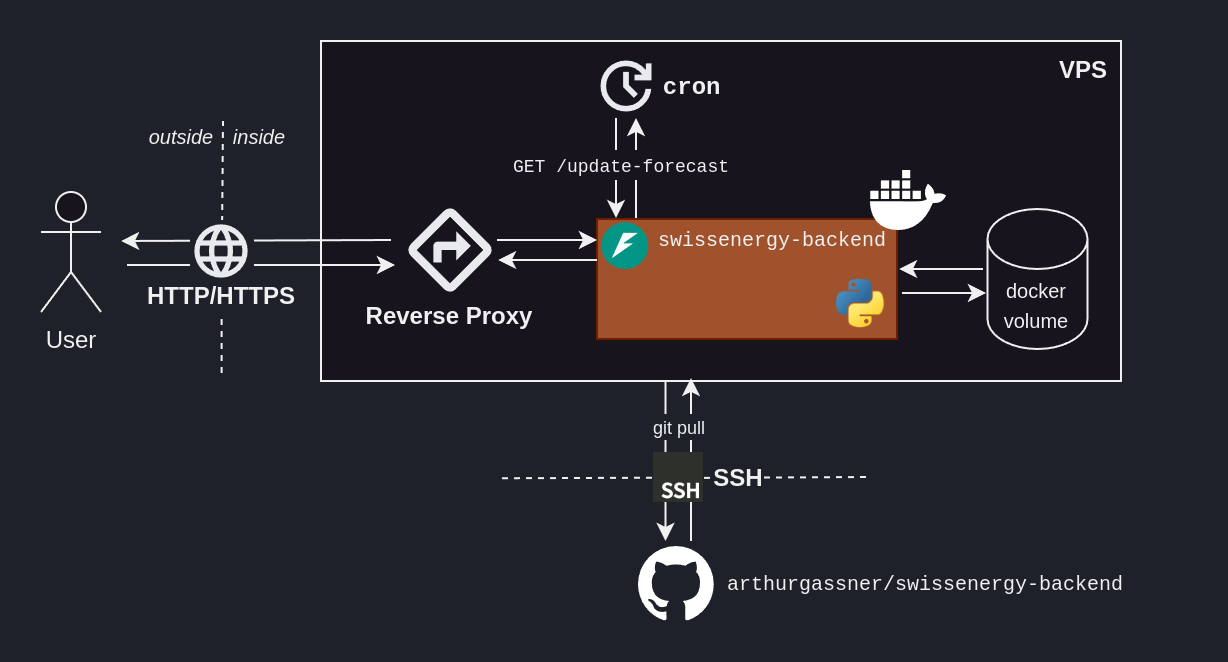
And here we are! An end-to-end ML solution, that our user can actually benefit from.
We’re nearing the end of our journey. As expected, the steps towards a deployed model were as follows:
- Problem understanding: What problem are we trying to solve? In what context?
- Data ingestion: What data can we access to solve this problem? How?
- Exploratory Data Analysis (EDA): What does that data look like?
- Modelling: How can we use that data to solve our problem?
- Industrialization: How can we prepare our solution for it to be used by other people?
- Deployment: How can the people having the initial problem use our solution?
Naturally, the work doesn’t end here. We’ll hear back from our user, and – potentially – address their comments by making changes to our pipeline.
Congratulations to us on building – and most importantly shipping – our ML solution! 🎆🥳
Potential future work
Building this side-project, I kept going back and improving things I had built in previous stages.
This iterative approach is normal, and fundamental to the ML engineering work.
Regardless, an unused ML solution is a failed ML solution. As such, we must get to the last stage – deployment – and ship. Doing so fosters insights, and improvement ideas.
Make it work, make it right, make it fast
To deliver, we must get to the end.
It is easy – especially as engineers – to get lost in premature optimization. To go forward:
First, make it work.
Then, make it right.
Finally, make it fast.
A trick we can use to prevent us from premature optimization is to gather our improvement ideas somewhere, so that we know when to look if these improvements end up making sense. This section is this project’s somewhere.
Data ingestion
- We only considered the
ENTSO-Edata and noticed their reportedActual Loadgets updated within 1-2 weeks. How about leveraging other energy data sources? - We predicted future energy data from past energy data. The weather is likely a strong predictor of energy consumptino. How about enriching our model with weather data – e.g. from MeteoSuisse?
Modelling
- We focused on an LGBM-based approach from the get-go. How about exploring other models?
- We selected our features by intuition. How about approaching feature selection – and model selection – in a more methodical and scientific manner, e.g. with
SHAPandoptuna? - We built our model to solve the “Predict the load in 24h”, but it seems like it isn’t what the ENTSO-E model is solving. How about figuring out what problem they’re solving to better understand their context?
Industrialization
- We focused on getting something that could run, with little thought to computation cost. How about reusing past predictions if the features haven’t changed?
- Our testing strategy focused on unit tests. How about implementing integration tests? How about testing the generated Docker image?
- Every hour, we retrain 24 models – for the 24 hours. How about re-using past data – that hasn’t been updated by the
ENTSO-Eand save on computation cost? - Past models are not kept track of. How about tracking the training performance through MLOps tools, e.g. with
MLflow?
Deployment
- To update the server, we manually SSH into it, pull from the repo, build the new Docker container and start it. How about automating this process, leveraging the
Docker Hub, orGitHub Webhooks?